
Introduction
More and more tourists are visiting The Netherlands, this will become very clear if you walk through the center of Amsterdam on a sunny day. All those tourists need to eat somewhere, in some restaurant. You can see their sad faces as they have no clue where to go. Well, with the aid of a little data science I have made it easy for them :-). A small R Shiny app for tourists to inform them to which restaurant they should go in The Netherlands. In this blog post I will describe the different steps that I have taken.

Tourists in Amsterdam wondering where to eat……
Iens reviews
In an earlier blog post I wrote about scraping restaurant review data from www.iens.nl and how to use that to generate restaurant recommendations. The technique was based on the restaurant ratings given by the reviewers. To generate personal recommendations you need to rate some restaurants first. But as a tourist visiting The Netherlands for the first time this might be difficult.
So I have made it a little bit easier, enter your idea of food in my “Bon Appetit“ Shiny app, it will translate the text to Dutch if needed, then calculate the similarity of your translated text and all reviews from Iens, and then give you the top ten restaurants whose reviews matches best.
The Microsoft translator API
Almost all of the reviews on the Iens restaurant website are in Dutch, I assume that most tourists from outside The Netherlands do not speak Dutch. That is not a large problem, I can translate non Dutch text to Dutch by using a translator. Google and Microsoft offer translation API’s. I have chosen for the Microsoft API because they offer a free tier. The first 2 million characters are free per month. Sign-up and get started here. And because the API supports the Klingon language….. 🙂
The R franc package can recognize the language of the input text:
lang = franc(InputText) ISO2 = speakers$iso6391[speakers$language==lang] from = ISO2
The ISO 2 letter language code is needed in the call to the Microsoft translator API. I am making use of the httr package to set up the call. With your clientID and client secret a token must be retrieved. Then with this token the actual translation is done.
#Set up call to retrieve token
clientIDEncoded = URLencode("your microsoft client ID")
client_SecretEncoded = URLencode("your client secret")
Uri = "https://datamarket.accesscontrol.windows.net/v2/OAuth2-13"
MyBody = paste(
"grant_type = client_credentials&client_id=",
clientIDEncoded,
"client_secret=",
client_SecretEncoded,
"&scope=http://api.microsofttranslator.com",
sep="";
)
r = POST(url=Uri, body = MyBody, content_type("application/x-www-form-urlencoded"))
response = content(r)
Now that you have the token, make a call to translate the text
HeaderValue = paste("Bearer ", response$access_token, sep="") TextEncoded = URLencode(InputText) to = "nl" uri2 = paste( "http://api.microsofttranslator.com/v2/Http.svc/Translate?text=", TextEncoded, "&from=", from, "&to=", to, sep="" ) resp2 = GET(url = uri2, add_headers(Authorization = HeaderValue)) Translated = content(resp2) #### dig out the text from the xml object TranslatedText = as(Translated , "character") %>% read_html(pp) %>% html_text()
Some example translations,
Louis van Gaal is notorious for his Dutch to English (or any other language for that matter) translations. Let’s see how the Microsoft API performs on some of his sentences.
- Dutch: “Dat is hele andere koek”, van Gaal: “That is different cook”, Microsoft: “That is a whole different kettle of fish”.
- Dutch: “de dood of de gladiolen”, van Gaal: “the dead or the gladiolus”, Microsoft: “the dead or the gladiolus”.
- Dutch: “Het is een kwestie van tijd”, van Gaal: “It’s a question of time”, Microsoft: “It’s a matter of time”.
The Cosine similarity
The distance or similarity between two documents (texts) can be measured by means of the cosine similarity. When you have a collection of reviews (texts), then this collection can be represented by a term document matrix. A row of this matrix is one review, its a vector of word counts. Another review or text is also a vector of word counts, given two vectors A and B the cosine similarity is given by:
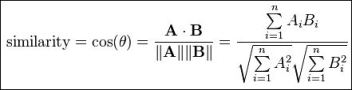
Now the input text that is translated to Dutch is also a vector of word counts and so can calculate the cosine similarity between each restaurant review and the input text. The restaurants corresponding to the most similar reviews are returned as recommended restaurants, bon appetit 🙂
Putting all together in a Shiny app
The above steps are implemented in my bon appetit Shiny app. Try out your thoughts and idea of food and get restaurant recommendations! Here is an example:
Input text: Large pizza with chicken and cheese that is tasty.
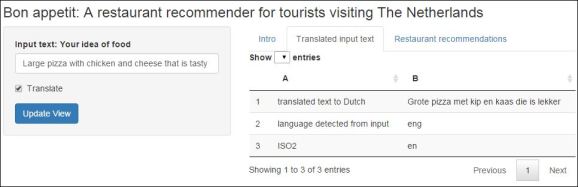
Input text translated to Dutch
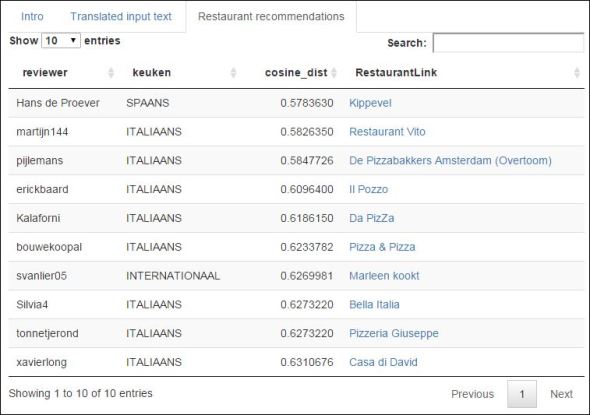
The top ten restaurants corresponding to the translated input text
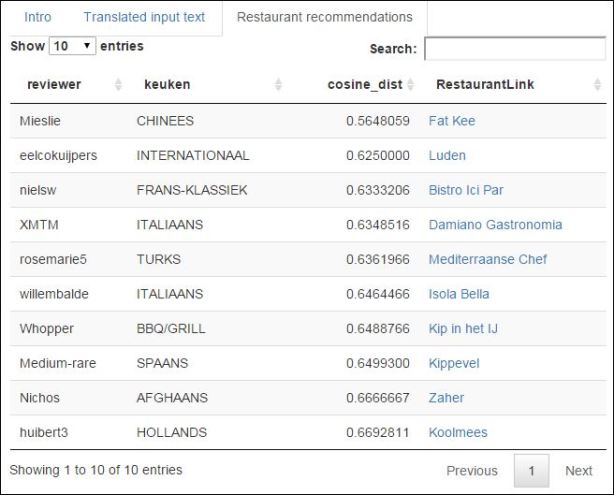
And for the German tourist: “Ich suche eines schnelles leckeres Hahnchen”, this gets translated to Dutch “ik ben op zoek naar een snelle heerlijke kip” and the ten restaurant recommendations you get are given in the following figure.
cheers,
— Longhow —







